Overview
An end-to-end computer vision pipeline that classifies houseplant health conditions (healthy vs. unhealthy) using Amazon Rekognition Custom Labels. Built with a production-style architecture including automated serverless inference via AWS Lambda. Every AWS resource was provisioned and managed entirely through Python, making the pipeline fully reproducible from a single notebook.


Architecture
Local Images → S3 Upload → Rekognition Custom Labels Training
↓
New Image → S3 (uploads/) → Lambda → Rekognition Inference → S3 (results/)
Results
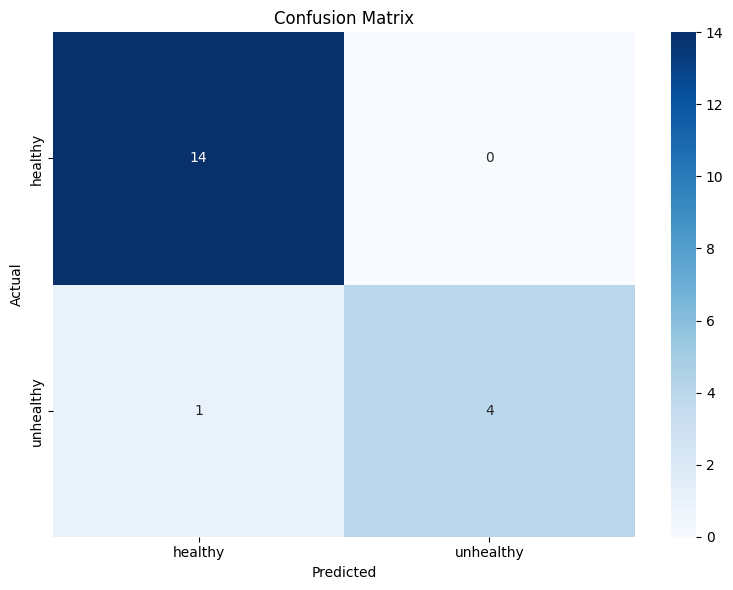
Performance evaluated on 19 holdout test images:
| Metric | Healthy | Unhealthy |
|---|---|---|
| Precision | 0.93 | 1.00 |
| Recall | 1.00 | 0.80 |
| F1 Score | 0.97 | 0.89 |
| Overall Accuracy | 0.95 |
Dataset
- 91 original images (67 healthy, 24 unhealthy) collected from personal houseplants
- Augmented to 201 training images to address class imbalance
- 80/20 train/test split with stratification
- Available on Kaggle: Houseplant Health Classification Dataset
Pipeline
- Images organized into healthy/unhealthy folders
- Train/test split (80/20) with stratification
- Augmentation applied to training set only via Albumentations
- Images uploaded to S3 with manifest files for Rekognition
- Rekognition Custom Labels model trained on 201 images
- Model evaluated against 19 holdout test images
- Lambda function deployed for automated inference on new S3 uploads
Tech Stack
Python Amazon Rekognition Custom Labels Amazon S3 AWS Lambda IAM Boto3 Albumentations Scikit-learn
Acknowledgements
Training images were collected in person at two plant nurseries whose staff were kind enough to allow photography:
- Holiday Foliage Orchids and Plants — 146 West 28th Street, New York, NY
- Redwood Flower Shop — New Brunswick, NJ